
Advances in Machine Learning & Artificial Intelligence(AMLAI)
ISSN: 2769-545X | DOI: 10.33140/AMLAI

Research Article - (2024) Volume 5, Issue 4
Data & AI for Industrial Application
Received Date: Oct 15, 2024 / Accepted Date: Nov 24, 2024 / Published Date: Dec 09, 2024
Copyright: �?�©2024 Antimo Angelino. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Citation: Angelino. A. (2024). Data & AI for Industrial Application. Adv Mach Lear Art Inte, 5(4), 01-07.
Abstract
The use of Artificial Intelligence in the Industry can lead to recovery of efficiency for industrial processes (such as reduce scrap and rework rate, increase throughput time), and this can carry competitive advantages. Nevertheless, to correctly deploy artificial intelligence projects it is needed to have connectivity and quality data. Both are enabling factors for AI projects, and industries must put in place processes to reach them before to start the AI journey.
Keywords
Artificial Intelligence, Data Analytics, Data Quality, Data Strategy, Industrial Network
Introduction
Where AI Comes From
The Artificial Intelligence (AI) is something wider and older that the hype of last years. Its birth can be dated back to 1943 when McCulloc and Pitts introduced the concept of artificial neurons for the first time. Concept then taken up by Rosenblatt in 1958 who presented the first artificial neural network: the perceptron. In the middle, Alan Turing (the father of computer science) in 1950 introduced the concept of an intelligent machine. In its life AI has undergone various ups and downs and the alternating fortunes have always been linked to successes in real use cases or to the emergence of favorable technological conditions, as well as periods of abandonment have been conditioned by the failures in projects too ambitious or not yet technologically mature. Since the mid-2000s there has been a rediscovery of AI thanks to the birth of a branch that is well suited to the resolution of predictive problems: the machine learning (ML).
Figure 1 shows the relationship between AI, ML, DL (deep learning) and GEN_AI (generative AI), which we could briefly define as:
• AI: any technique that makes computers capable of imitating human behavior; among these we remember the most emblematic:
o expert systems: capable of simulating deductive logical reasoning
o fuzzy logic: capable of introducing uncertainty management into logical reasoning o genetic algorithms: which, by imitating natural selection, are able to identify the optimal solution to a given problem;
o artificial neural networks: systems that simulate the neural networks of our brain are able to learn from data and extrapolate behaviors and information;
• ML: specific AI techniques that make computers capable of learning;
• DL: a subset of ML techniques specifically based on deep (or multilayer) neural networks suitable for solving computer vision, image recognition and signal processing problems;
• GEN_AI: a sub set of DL that use NLP (natural language processing) technique to elaborate text and predict sentence starting from an input (prompt).
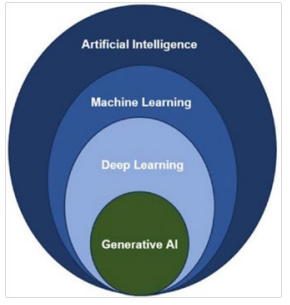
Figure 1: Relationship between AI and its major frameworks application
What means Industrial Domain
With the reference “industrial domain” we means all the processes involved into manufacturing, maintenance and quality activities of industries; where industry start when raw materials arrive and finish when manufactured item is delivered, so excluding supply chain and customer support.
The data involved into the industrial domain are generated by manufacturing and test machines and by IIoT (industrial internet of things) sensors; nevertheless also specific data contained into the MRP (manufacturing resource planning), MES (manufacturing execution system) and QMS (quality management system) are involved.
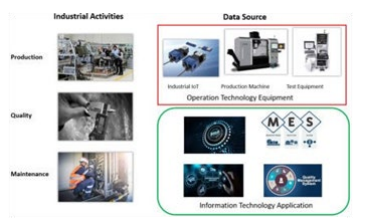
Figure 2: what is Industrial Domain
Not only the source but also the type and format of these data are very different: data coming from machines and sensors (normally located on the shop floor) are raw data without the minimum requirement for trustworthiness and quality, and so they need to be pre-processed before to be used; data coming from main informative systems are normally trusted date, because there are in place processed to control and validate them before charged into the systems.
Besides the collection of the data is very complex due to the different nature of their sources. In fact the main informative systems are normally available over the company enterprise network, while machines and sensors are often isolated and when connected they are appended to a special network (normally called edge network). Due to cyber security risks, it is not possible to connect directly the two type of network. Therefore, to collect all the data it is necessary to put in place and industrial network according the standard ISA-IEC 62443 (known also as ISA-99, that replaced the ISA-95 the first standard for Industrial Network).
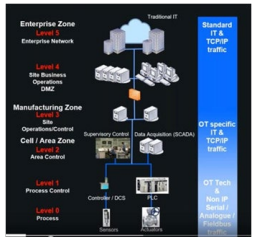
Figure 3: industrial network schema
AI in the Industrial Domain
However, the birth of ML was not the only triggering factor behind the rediscovery of AI in the new millennium, but rather there was a mix of accelerating factors such as:
• The exponential increase in data availability, thanks to the internet, connectivity systems (both wired and mobile) and intelligent sensors (commonly called IoT = Internet of Things);
• The possibility of collecting data in real time, thus providing an instant representation of reality;
• The constant increase in computing power combined with the miniaturization of devices available at ever-decreasing costs (at least until pre-Covid) All this has placed data at the center of decision- making strategies, effectively evolving decision- making models from knowledge models based or based on knowledge (often empirical and built with experience), to data driven models .
A first effect induced by this epochal change is that while knowledge-based models were (and still are) used mainly for descriptive analysis (i.e. describing an event that occurred), data-driven models can be used for predictive analyses. (i.e. predicting an event before it happens).
Therefore, if data constitute the fuel of new decision- making models, data analytics and advanced data analytics techniques constitute their engine. In particular, while data analysis techniques are essentially based on the most common statistical formulas and are used to describe an event and diagnose its cause; the advanced ones are based on AI (mainly ML) algorithms and used to predict an event and prescribe actions to influence it. Figure 4 (Gartner 2012) shows the evolution of data analytics in four phases: descriptive, diagnostic, predictive and prescriptive; depicted in a Cartesian plane whose axes represent the value (returned by the analysis) and the difficulty (of the analysis itself).
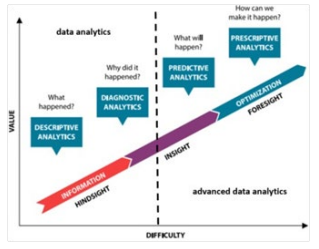
Figure 4: Gartner data analysis phases
The Figure 5 illustrates how the adoption of data-driven decisionmaking models combined with advanced analysis techniques enables another epochal change in business processes: the anticipation of corrective actions. Therefore moving from a reactive approach, i.e. chasing the problem after the event; to a predictive one, i.e. anticipating the problem before the event happens.
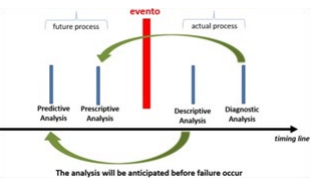
Figure 5: timing line of data analysis
Predictive and prescriptive analyzes have been used for years in various sectors: from financial to risk management, from marketing to communication and even politics; always with the aim of predicting events and (trying to) influence them through targeted actions.
In the industrial domain, the principal application is the prediction of failures, both on the product and on the machinery, and the prescription of actions aimed at ensuring that they do not occur. In fact, these applications have a direct impact on the efficiency and effectiveness of industrial processes, and consequently on competitiveness and cost reduction of companies. There are various declinations and use cases implemented in industries, which have given rise to different methodologies:
• failure prediction (prediction of product failures),
• predictive quality (prediction of product quality),
• predictive maintenance (prediction of machinery failures).
The adoption of predictive systems in the industrial world, although pushed by managers who see the potential benefits, often encounters the reluctance of technicians who, accustomed to analyzes based on empirical experience, have difficulty accepting the predictions made from a heuristic model using ML algorithms. Therefore, a fundamental step for a predictive model to be accepted (and consequently then correctly used) is to demonstrate its reliability: its predictions and prescriptions are true. To do this the model validation phase is fundamental; it takes place after the training and testing phases. This phase is developed using real data, i.e. historical data recorded in the company and referring to real events: the predictive model, once trained and tested, is asked to provide a prediction starting from known data; the model's prediction is acquired and compared with what really happened.
To give some more elements, it is necessary to divide the predictive models based on their applications: regression models and classification models. The former are models that predict values, while the latter predict the classification of an event. A classic explanatory example is the predictive meteorology systems: a regression system predicts the temperature value, a classification model whether the day will be sunny, cloudy or rainy. The most commonly used metrics for validating these models are:
• RMSE (Root Mean Squared Error) for regression models
• Confusion Matrix for classification models
The first metric consists of calculating the square root of the mean square error between the value predicted by the model and the actual value recorded in the company. An acceptable error value is less than 3%. The confusion matrix , on the other hand, is a slightly more complex metric, which is based on the combination of the exact and incorrect classifications made by the predictive model compared to the real ones. Figure 4 illustrates this in a very intuitive way. The parameters of confusion matrix should have a value greater than 95%.

Table 1: Confusion Matrix
Data Strategy
We can use a SOWT matrix to resume the use of AI in the industrial domain.
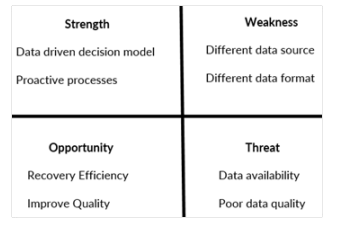
Table 2: SWOT matrix for AI adoption
It is so clear that managing data is the most critical part in the deployment of an AI project. In particular, the industrial domain there are completely different data source and data format.
First it is necessary to identify all data sources and define how to connect them to allow data collection and assure the possibility to recovery data in continuous and automatic way. After that it is necessary to identify (for each data source) the data format, so to label them and create a data catalog. It is important to note that not all the data generated are in a format “ready to use” for an AI model. Often it is necessary to pre-process the data with specific actions (i.e. cleaning, pruning, filtering, augmenting, etc.) to transform them from raw data to quality data. In particular in the industrial domain all the data generated by machines and sensors are normally raw data. It is therefore important in this phase to well define which pre-processing activities are necessary to transform raw data into quality data. International standards are available and can be used as reference:
• ISO/IEC 8183:2023 - Data Life Cycle Framework
• ISO/IEC 42001:2023 - Artificial intelligence Management System
• ISO/IEC DIS 5259-1 - Data quality for analytics and machine learning
In conclusion it is necessary that companies put in place a data strategy to correctly manage their data, setting specific processes with dedicated role profiles. An appropriate data strategy will safe companies against the threat of collecting big amount of data not useful for an AI model.
The Table 3 shows the principal activities for a Data Strategy, with indication of specific role profiles (data steward and data engineer) to set up in the business divisions. Normally a role of data architect is set up in the information technology division to manage data catalog and data storage policie.
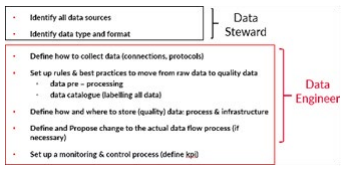
Table 3: main principles of a data strategy
Safeguards and Ethics
A problem that often emerges and leads models to make incorrect predictions is the bias (conditioning) of the data. In fact, a fundamental element for a model to make reliable predictions is that the data with which it is trained and tested are representative of the event it wants to predict. If the data only partially represents the event or represents a distorted view of it, even if the predictive model passes the training and testing phases, it will then make incorrect predictions. Furthermore, since, by their intrinsic nature, it is difficult to analytically verify the behavior of an AI- based predictive model. Therefore to mitigate the effects of an incorrect prediction, the concept of risk management was introduced, which provides control mechanisms on decisions taken following predictions with the intention of limiting potential induced errors. The practice is now an international standard, which finds its place in the reference document ISO/IEC 23894. Also the recent EU AI ACT is based on the risk management. The figure 6 shows the level of risk based on the AI model implication. For example an autonomous system that classify spam email is considered as low risk, while a system used for social scoring is an unacceptable risk.
The problems inherent to the possibility of incorrect behavior of predictive models based on AI, added to the difficulty of analytical and timely feedback, lead to a much broader reflection that introduces the topic of ethics in the use of AI: what use should we make of AI? How much decision-making autonomy can we leave them? On the first, a conscious use of AI can help automate tasks that are currently manual and repetitive, giving a notable boost to industrial processes. The second question is much more complex: can AI-based systems be autonomous in making decisions and carrying out actions or do they only have to suggest a decision (or action) which the human must then validate and execute? In this case we talk about the dualism "autonomous systems vs human in the loop systems". The former are systems in which AI is given the opportunity to make decisions and carry out actions, in the second case the AI systems process the information and then suggest a decision or action that the human being must validate. The analysis is not trivial: there has been discussion about autonomous systems for years and various experiments and research have been conducted in many fields of application, but to date no system has fully convinced.
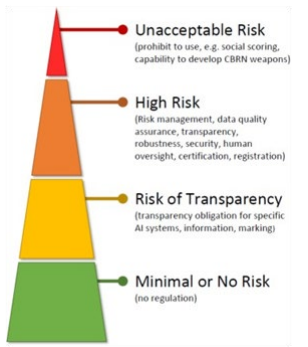
Figure 6: EU AI ACT risk management
The latest research frontier in this field is called explainable artificial intelligence (XAI) and was introduced by Michael Van Lent in 2004. Its scope is to give put in clear the activities done by an AI system during its training, testing and execution phases.
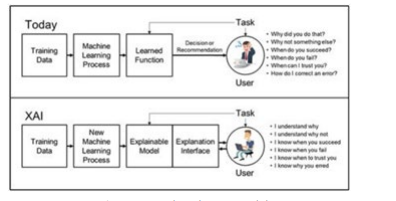
Figure 7: explanation AI model
AI & Quantum Computing
An important step in the AI systems is the quantum machine learning (QML), it is the combination of machine learning and quantum computing with the aim to use the machine learning model on the quantum computers. There are a lot of research on this field in academic world, while there are growing the first proof of concept application in the industrial companies. Nevertheless there is still a lot of work to do: the quantum computer for industrial application will be available probably within 5-7 years; while the classical machine learning models are not yet all transformed into quantum one.
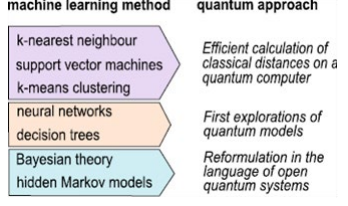
Figure 8: quantum machine learning models
Conclusion
In conclusion, AI and its growing applications in industries can represent an opportunity to achieve otherwise unattainable target. Nevertheless we must know and govern AI, in order to use it in correctly and exploiting all its potential in the way most suited to the application context and comfortable to industries operating way.
References
1. McCulloch, W. S., & Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity. The bulletin of mathematical biophysics, 5, 115-133.
2. Rosenblatt, F. (1958). The perceptron: a probabilistic model for information storage and organization in the brain. Psychological review, 65(6), 386.
3. Turing, A. M. (2009). Computing machinery and intelligence (pp. 23-65). Springer Netherlands.
4. A. Angelino. (2013). “L’Intelligenza Artificiale.”Ingegneri Napoli 1: 3-10
5. A. Angelino. (2022). “L’Intelligenza Artificiale per i processi industriali.” Sistemi & Impresa 4: 28-32.
6. A. Angelino. (2022). “La convergenza tra IT ed OT.” Sistemi & Impresa 2: 36-39.
7. E. Rich., K. Knight. (1994). Intelligenza Artificiale, seconda edizione, McGraw Hill Italia.
8. Hecht-Nielsen, R. (1989). Neurocomputing. Addison-Wesley Longman Publishing Co., Inc..
9. Norvig, P., & Russell, S. J. (2010). Intelligenza artificiale. Un approccio moderno.
10. Van Lent, M., Fisher, W., & Mancuso, M. (2004, July). An explainable artificial intelligence system for small-unit tactical behavior. In Proceedings of the national conference on artificial intelligence (pp. 900-907). Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999.
11. Schuld, M., Sinayskiy, I., & Petruccione, F. (2015). An introduction to quantum machine learning. Contemporary Physics, 56(2), 172-185.